Voluntary vs Involuntary Churn: A SaaS Playbook for 2026
Ayush Soni
Founder, Revcover

On this page
- The Two Faces of Churn Definitions and Impact
- Voluntary churn is intent-driven
- Involuntary churn is systems-driven
- The Voluntary Churn Playbook Winning Back Active Choices
- Build the cancel flow around decision quality
- Route people into save paths that fit the reason
- Define the handoff rules before launch
- The Involuntary Churn Playbook Recovering Failed Payments
- Start with event classification, not generic dunning
- Build the workflow by team, not by tool
- Use a timed recovery sequence
- Measure recovery in MRR, not message volume
- Escalate based on value and context
- Detecting and Measuring Churn Effectively
- Use different data sources for each churn type
- Track intervention-level outcomes
- Operationalizing Churn Reduction Across Teams
- RevOps runs the system of record for intervention logic
- Product and CS close the loop differently
- Building Your Churn-Fighting Stack with Revcover
A lot of teams still talk about churn like it's one number with one fix. That's how revenue leaks for quarters.
The better framing starts with one uncomfortable fact. Involuntary churn from failed payments accounts for 20–30% of total subscription churn in SaaS businesses, and recovery rates of 65–70% are achievable when retries, email, and in-app reminders are coordinated within 24–48 hours of payment failure, according to Revcover's summary of involuntary churn statistics. That should reset how you think about retention. A meaningful share of lost MRR has nothing to do with product dissatisfaction. It's an ops problem.
But the rest of churn often does involve an active customer decision. That's a different motion entirely. A user clicking cancel because they don't see value needs a different response than a healthy account with an expired card. If you run both through the same workflow, you usually get the worst of both worlds: bad save offers for voluntary churn, weak payment recovery for involuntary churn, and reporting that tells you almost nothing about what worked.
The strongest churn programs split the problem in two from day one. One playbook is built for active choice. The other is built for passive failure. Both need clear ownership across RevOps, Product, Customer Success, billing, and your Stripe-connected stack. Both should tie every intervention back to recovered MRR, not just activity.
The Two Faces of Churn Definitions and Impact
Most churn reporting hides the main distinction that matters operationally. Voluntary churn happens when the customer chooses to leave. Involuntary churn happens when the subscription lapses because billing fails, access expires, or a payment issue goes unresolved.
That sounds basic, but teams routinely blur the two. They look at one gross churn number, then throw lifecycle emails, discounting, CS outreach, and billing reminders into the same bucket. The result is messy attribution and poor execution.
Voluntary churn is intent-driven
Voluntary churn usually starts with behavior you can observe before cancellation. Usage drops. A key feature goes untouched. Stakeholders stop logging in. Support tickets shift from onboarding questions to friction, pricing, missing workflows, or competitor comparisons.
The customer is making an active tradeoff. They may still value the product, but they no longer think the current plan, timing, price, or experience makes sense. That's why the save motion has to be contextual. You're not solving collections. You're trying to alter a decision.
Involuntary churn is systems-driven
Involuntary churn has a different shape. The product may still be delivering value. The account may even be healthy. But the card expires, a bank declines the charge, the issuer blocks the attempt, or the billing contact misses the notification.
That makes involuntary churn more operational than persuasive. You don't need a better pitch. You need faster detection, retry logic, clear communication, and a frictionless way to update payment details.
Here's the cheat sheet I use with teams when we're rebuilding churn reporting.
| Characteristic | Voluntary Churn | Involuntary Churn |
|---|---|---|
| Customer intent | Active decision to cancel | No deliberate cancellation required |
| Typical trigger | Price, fit, value, missing capability, timing, internal change | Card expiry, decline, billing failure, payment setup issue |
| Earliest signals | Cancellation page visit, downgrade interest, usage decline, exit feedback | Failed invoice, retry failure, payment method issue |
| Best owner | Shared across RevOps, Product, and CS | Shared across RevOps and billing/finance, with support backup |
| Best intervention | Save path tailored to reason and account context | Smart retries, reminders, card update flow, service restoration |
| Bad intervention | Generic discount for everyone | One email and then immediate account termination |
| MRR impact pattern | Often tied to product or commercial root causes | Often recoverable through process and timing |
| Core reporting need | Reason capture plus save-path attribution | Failure-code tracking plus recovery attribution |
Practical rule: If a customer says they want to leave, treat it like a product and commercial signal. If a payment fails, treat it like a recoverable operations issue until proven otherwise.
Once you separate the two, better decisions follow quickly. Product gets cleaner feedback. CS knows which accounts deserve human outreach. RevOps can measure which offers save MRR and which retry logic restores subscriptions. That split is the foundation for everything else.
The Voluntary Churn Playbook Winning Back Active Choices
A default cancel button teaches customers to leave faster. It doesn't learn why they're leaving, and it gives your team no chance to respond intelligently.
The better pattern is a structured cancellation flow connected to Stripe and the rest of your operating stack. The point isn't to trap people. It's to present the right option at the exact moment they've signaled intent.
Build the cancel flow around decision quality
A strong cancel flow does three things in sequence.
First, it captures the reason in a structured way. Don't rely only on freeform text, and don't rely only on dropdowns either. Give customers a reason category, then let them explain it in their own words. That combination is what lets RevOps report themes and lets Product read the nuance behind them.
Second, it enriches the moment with account context. Plan type, tenure, recent usage, open support issues, expansion history, billing status, and contract posture should all shape the next step. A low-usage self-serve account and a high-value account with recent product friction should not see the same path.
Third, it presents a credible alternative. However, organizations often overlook this aspect. They ask why someone is leaving, then force them through a generic “are you sure?” screen. That doesn't respect the signal.
Route people into save paths that fit the reason
The save path library should be opinionated. Not every reason deserves an offer, and not every offer should be a discount.
A practical library usually includes:
- Pause for timing issues: If the customer says they don't need the product right now, offer a pause instead of a full cancellation. This works best for seasonal usage, project-based work, hiring freezes, or temporary budget holds.
- Downgrade for budget pressure: If the issue is price, a lower-cost plan or reduced seat count is often better than a blanket discount. You preserve the relationship and avoid retraining customers to ask for concessions.
- Targeted discount for narrow cases: Use discounts selectively. They're useful when a customer still sees value but needs a short bridge. They're harmful when they mask a product gap.
- Support handoff for unresolved problems: If the user cites a broken workflow, poor onboarding, or a blocked implementation, route them to support or success instead of showing a pricing offer.
- Sales or CS intervention for high-value accounts: Some accounts deserve a live conversation because the upside is larger than the cost of outreach.
- Clean cancellation when that's the right answer: If there's no credible save path, let them leave cleanly and preserve goodwill.
The best save offer isn't the one with the biggest concession. It's the one that matches the reason the customer is trying to cancel.
There's a useful analogy from attention research. In spatial-cueing studies, voluntary attention with predictive cues improves perceptual representation and can raise accuracy by 15–20% when tasks are difficult, while involuntary attention with nonpredictive cues shows a 10–12% accuracy drop under the same conditions. The same body of work also found stronger benefits for predictive, validly cued conditions than for generic prompts. For retention teams, the lesson is straightforward: personalized, predictive save paths work better for complex cancellation decisions than broad, noncontextual interruptions.
Define the handoff rules before launch
The workflow fails if the right team hears about the risk too late. Build the routing rules before you publish the flow.
A workable operating model looks like this:
- RevOps owns logic and instrumentation. It defines cancellation reasons, maps them to routes, and sets thresholds for when an account gets self-serve treatment versus human intervention.
- Customer Success receives high-priority alerts. High-value accounts, strategic logos, and customers with recent expansion potential should trigger immediate notifications in the team's existing channels.
- Product receives classified feedback. Product doesn't need every individual cancellation. It needs grouped themes with associated MRR so it can prioritize root-cause fixes.
- Finance and billing stay out of voluntary saves unless billing is part of the issue. Keep ownership clean.
Don't judge this motion by cancellation-page conversion alone. Judge it by whether the save path changed the subscription outcome and whether the captured reason improved your roadmap, pricing decisions, or CS outreach quality.
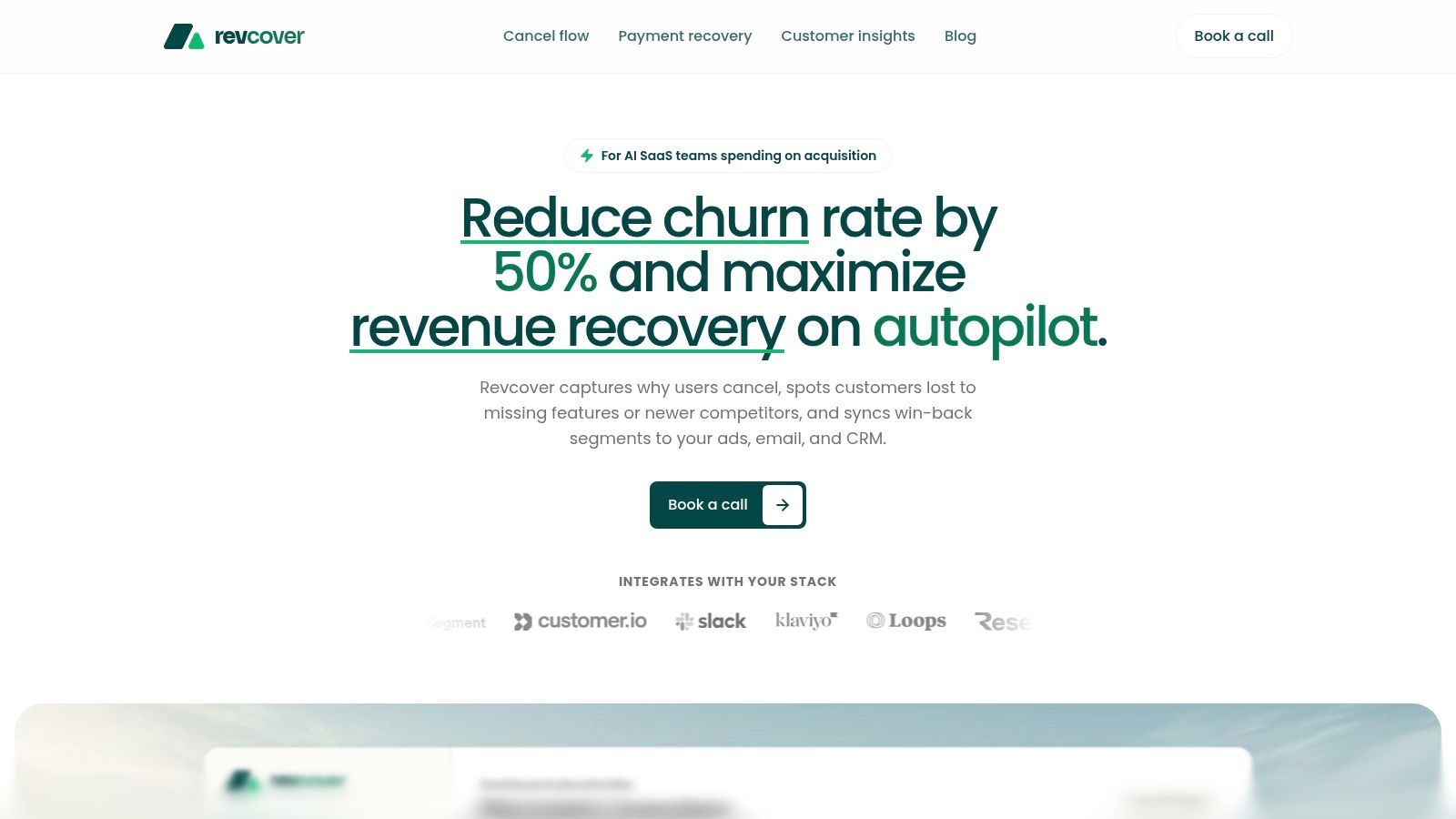
The Involuntary Churn Playbook Recovering Failed Payments
Failed payments usually look like a billing problem. In practice, they are an operating model problem. Revenue is lost when Stripe, lifecycle messaging, in-app prompts, and account ownership are not wired into one recovery path.
This playbook should be built for speed and triage. RevOps needs immediate event capture from Stripe and clear routing logic. Product needs the right billing surfaces in-app so customers can fix the issue without hunting through settings. CS should only step in when the account value or contract risk justifies human time.
Start with event classification, not generic dunning
A failed invoice should trigger a workflow, not a single email. The first job is to classify the failure so the customer gets the right next step fast.
Stripe-connected teams should separate at least four cases:
- Expired card: Ask for an updated payment method immediately.
- Soft decline: Retry on a controlled schedule and message the customer while the charge is still recoverable.
- Hard decline: Push straight to payment-method replacement.
- Issuer or bank decline: Explain the likely cause and give the customer a direct update path. This guide to a card declined by issuer is a useful example of the billing issue your logic should recognize.
That classification changes more than copy. It determines retry timing, channel mix, and whether the account stays fully active, enters a grace period, or gets routed to a human owner.
Build the workflow by team, not by tool
The best recovery programs are explicit about handoffs.
RevOps owns the billing recovery logic. That includes Stripe event ingestion, failure-code mapping, retry schedules, grace-period rules, MRR-based escalation thresholds, and reporting on recovered revenue.
Product owns the in-app recovery path. The billing banner, modal, or settings entry should open directly to the payment update flow. If the product makes users click through three screens to fix a card, recovery rates drop and support tickets rise.
Customer Success owns named-account intervention. CS should not chase every failed payment. It should receive alerts only for accounts that are large enough, strategic enough, or commercially sensitive enough to justify outreach.
Finance or billing ops owns exception handling. Tax issues, invoice disputes, procurement delays, and payment-method edge cases often sit outside standard dunning. Give those cases a clean queue instead of burying them in CS.
Use a timed recovery sequence
Good dunning is a sequence with deadlines, channels, and stop conditions.
A practical motion looks like this:
| Time from failure | System action | Team action |
|---|---|---|
| Immediate | Capture Stripe event, classify decline, trigger first message with direct payment update link | RevOps monitors event health |
| 24 to 48 hours | Retry based on failure type, send reminder, show in-app prompt on login | No human action for standard accounts |
| 3 to 5 days | Escalate messaging, tighten product visibility if needed, retry where appropriate | CS alerted for high-MRR or strategic accounts |
| Final recovery window | Apply access restriction or service hold based on policy | Billing or CS handles exceptions before cancellation |
The trade-off is simple. Aggressive restriction can recover some accounts faster, but it can also frustrate customers who would have fixed the issue with one reminder. For most SaaS businesses, a grace-period model with clear prompts performs better than immediate feature removal.
Measure recovery in MRR, not message volume
Open rates and click rates are secondary. The scoreboard for involuntary churn is recovered MRR, time to recovery, and avoidable cancellations prevented.
Track these numbers at minimum:
- Failed-payment MRR at risk
- Recovered MRR by failure type
- Recovery rate by retry attempt
- Time from failure to payment-method update
- Human-save rate for CS-escalated accounts
- Final churned MRR after the dunning window closes
I also recommend reviewing recovery performance by segment. SMB self-serve accounts usually respond best to clear automation and a fast update flow. Enterprise accounts often need account-owner intervention because the blocker is internal approval, procurement, or a shared corporate card.
Escalate based on value and context
Human outreach should be selective and tied to commercial impact.
Use a simple decision model:
| Situation | Best next move |
|---|---|
| First failure, active product usage, low account value | Automated retry plus self-serve payment update |
| Repeated failure, active usage, no payment update | Add stronger in-app prompt and second reminder |
| High-MRR account, recent expansion, or open renewal | Route to CS or account owner for direct outreach |
| Long-overdue balance with ongoing usage | Apply access restriction based on policy, then move to cancellation |
The goal is not to send more reminders. The goal is to recover revenue with the least friction possible, while making ownership clear across RevOps, Product, CS, and billing.
Detecting and Measuring Churn Effectively
Most churn dashboards answer the wrong question. They tell you how much MRR you lost. They don't tell you which intervention changed the outcome or which team needs to act next.
A useful dashboard starts by separating churn into two pipelines, then measuring each one with different inputs and different success criteria.
Use different data sources for each churn type
For voluntary churn, your best inputs are cancellation reasons, freeform exit comments, usage patterns, support history, and account attributes. The cancel event itself is only the end marker. Primary diagnostic value comes from why the customer left and what account context surrounded that decision.
For involuntary churn, the primary signals are payment events, retry outcomes, billing contact behavior, and payment-method changes. You need a cleaner operational view than most BI layers provide by default.
That's why I push teams to maintain two parallel detection models:
- Intent model for voluntary churn: Looks at cancellation flow events, route selection, accepted offers, rejected offers, and eventual subscription outcome.
- Billing recovery model for involuntary churn: Looks at failed payment events, retry attempts, card updates, communication opens where available, and restoration status.
If your current analytics setup is too shallow, build a retention-specific layer. Teams that already care about engagement metrics for subscription products often have the raw behavioral data needed. They just haven't connected it to retention actions.
Track intervention-level outcomes
At a minimum, I want a churn dashboard to answer these questions:
- Which cancellation reasons are tied to the most at-risk MRR?
- Which save paths are accepted, and which lead to retained subscriptions?
- Which failed-payment cohorts recover quickly, and which require escalation?
- How much MRR was recovered by each intervention type?
- Which product, pricing, or service issues show up repeatedly in churn feedback?
Measurement rule: Don't stop at “saved” or “recovered.” Track whether the account stayed active after the intervention and whether the revenue remained durable.
This is also where teams overcomplicate attribution. You don't need a perfect econometric model to start. You need a reliable event chain. Customer started cancel flow. Customer selected reason. System showed offer. Customer accepted or rejected. Subscription changed or didn't. Billing failed. Retry happened. Payment updated. Access restored.
Once that event chain is stable, you can segment by plan, cohort, billing status, acquisition source, customer size, or onboarding stage. That's when the dashboard stops being descriptive and starts guiding resource allocation.
Operationalizing Churn Reduction Across Teams
Churn reduction breaks when one team owns the metric but not the workflow. The durable model is cross-functional, with explicit handoffs and a shared operating rhythm.
RevOps usually has to act as the coordinator because churn touches billing logic, product signals, lifecycle messaging, and frontline outreach. But RevOps shouldn't absorb all execution. It should run the system and route work to the right owners.
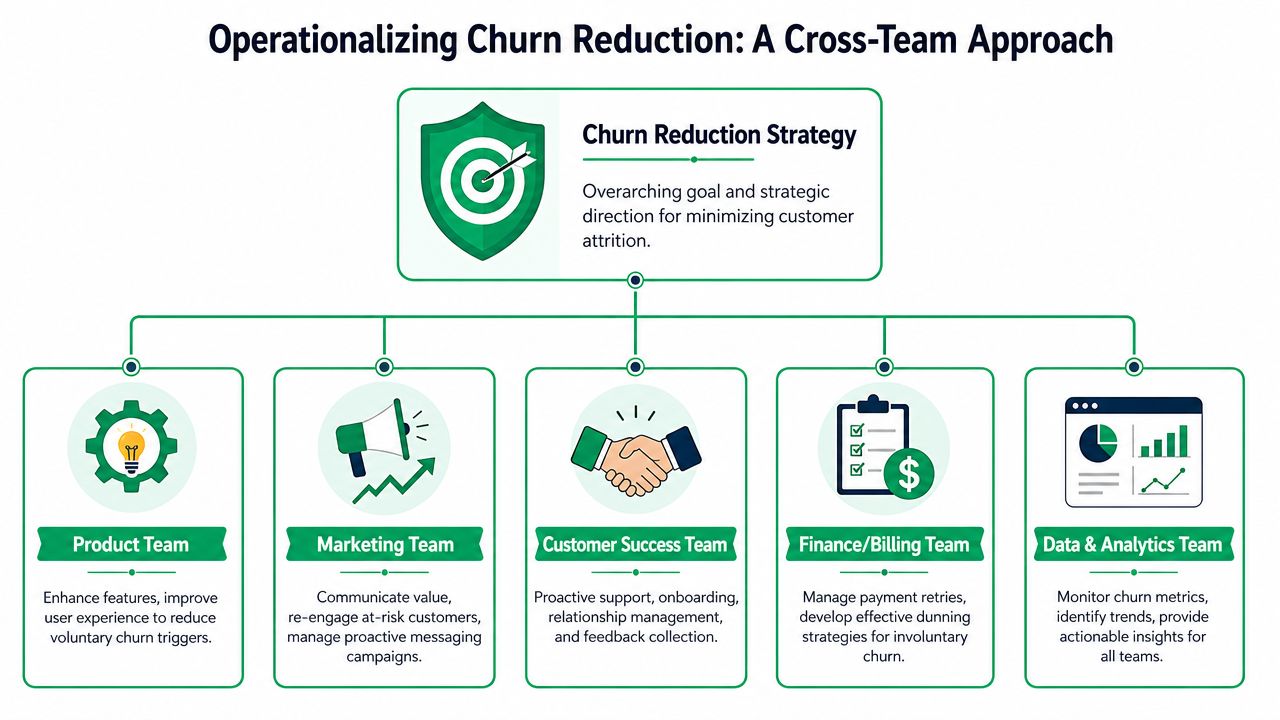
RevOps runs the system of record for intervention logic
The best RevOps teams own the mechanics that make the playbooks repeatable.
That means they define the cancellation taxonomy, configure routing rules, maintain the Stripe-connected event flow, and keep reporting aligned with actual subscription outcomes. They also decide which interventions are self-serve and which trigger human outreach.
In practice, RevOps should own:
- Routing logic: Which plan, usage pattern, stated reason, or billing state sends an account down which path.
- Offer governance: What save paths are available, where they appear, and when they're retired.
- MRR attribution: Which offer or recovery action gets credit for retained or restored revenue.
- Alerting and syncs: How events move into Slack, CRM, email platforms, and ad audiences.
Product and CS close the loop differently
Product and Customer Success both matter, but they shouldn't consume the same output.
Product needs grouped cancellation feedback tied to revenue context. If “missing integration,” “workflow limitation,” or “reporting gap” keeps showing up, Product should see that theme clearly and know its commercial impact. Product doesn't need every anecdote. It needs patterns with enough context to prioritize.
Customer Success needs account-level urgency. If a strategic customer signals cancellation intent, hits a billing problem during renewal, or abandons a save path after citing a specific issue, CS should get that alert fast enough to act while the account is still recoverable.
A practical team cadence often looks like this:
- Weekly RevOps review: Check save-path performance, failed-payment recovery flow health, and alert quality.
- Biweekly Product review: Review grouped churn reasons with associated MRR exposure and decide what belongs in discovery versus roadmap.
- Daily CS triage: Work high-priority alerts and document outcomes so the system learns which interventions deserve human time.
- Monthly leadership readout: Compare churn types, recovered revenue, unresolved themes, and process gaps.
Churn programs become reliable when every signal has an owner, every owner has a response window, and every response is measurable.
One more discipline matters. Keep the taxonomy stable long enough to learn, but not so rigid that nobody updates it when customer behavior changes. Teams often either change labels constantly or never revisit them. Both are mistakes.
Building Your Churn-Fighting Stack with Revcover
Running separate, improvised systems for voluntary and involuntary churn usually creates blind spots. One tool captures reasons but doesn't recover failed payments. Another sends billing emails but doesn't tie results back to MRR. A spreadsheet tries to hold the rest together.
That's why a unified retention layer matters. A platform like Revcover sits alongside Stripe Billing and handles the two motions in one operating system: cancellation interception for voluntary churn, payment recovery for involuntary churn, plus the reporting layer that connects actions to subscription outcomes.
For RevOps, that means fewer brittle hand-built flows. For Product, it means cleaner visibility into churn themes with revenue context. For CS, it means real-time alerts and clearer prioritization. For leadership, it means one place to see what's saving MRR versus what's just generating activity.
The strongest retention stack doesn't just reduce churn. It makes churn legible. That's what lets teams improve the product, tighten billing operations, and keep more recurring revenue without guessing.
If you want one system for cancellation flows, failed-payment recovery, and MRR attribution, Revcover is built for subscription SaaS teams running on Stripe. It helps you intercept cancellation intent, recover involuntary churn, route the right accounts to the right team, and measure which retention actions preserve revenue.